
В настоящий момент развитие и внедрение технологий на основе искусственного интеллекта (ИИ) является одним из приоритетных трендов современного здравоохранения. Одним из направлений применения ИИ является машинное обучение (МО) [1]. Программы, разработанные при помощи МО, позволяют значительно усовершенствовать систему диагностики, разработку новых лекарственных средств, а также повысить качество оказания медицинской помощи при одновременном снижении расходов. Основная задача МО заключается в создании программных продуктов, способных анализировать интеллектуальные задачи, для которых не существует алгоритмов решения, гарантированно приводящих к правильному результату [2]. Процессы, участвующие в МО, похожи на процессы интеллектуального анализа данных и прогнозного моделирования, необходимые для анализа шаблонов и соответствующей корректировки действий программы.
МО широко применяется в различных сферах медицины, в том числе и в области вспомогательных репродуктивных технологий (ВРТ) [3]. В репродуктивной медицине одна из наиболее важных задач МО заключается в том, чтобы по большому набору частных случаев наблюдения реконструировать зависимость между определенными характеристиками. Например, в зависимости от клинико-анамнестических данных супружеской пары определять частоту наступления беременности в программе ВРТ или в зависимости от качества сперматозоидов прогнозировать частоту бластуляции. Программы на основе МО лежат в основе экспертных систем, суть которых заключается в создании программы, имитирующей работу квалифицированного эксперта при принятии решения. В настоящий момент в области репродуктивной медицины большое внимание уделяется созданию экспертных систем для прогнозирования лечения бесплодия, выбора стратегии и тактики терапии, требующих учета совокупности имеющейся информации о супружеской паре, без чего медицинские решения носят приблизительный и «неточный» характер [4].
Стоит отметить, что ошибочное и неточное прогнозирование исхода программы ВРТ не позволяет своевременно ориентировать супружескую пару на использование того или иного метода лечения и корректировать ожидания пациентов в отношении частоты наступления беременности, а также препятствует целесообразному клинико-экономическому распределению средств Фонда обязательного медицинского страхования [5]. В связи с этим при разработке программного продукта задача прогнозирования эффективности программы ВРТ становится наиболее приоритетной.
Прогнозирование результативности программы ВРТ при помощи МО может быть осуществлено с использованием различных алгоритмов в зависимости от типа данных и поставленной задачи. Среди основных методов МО, используемых в репродуктивной медицине, выделяют логистическую регрессию, алгоритм решающего дерева, метод случайного леса (Random Forest) и градиентный бустинг над решающими деревьями (XGBoost, CatBoost) [6]. Логистическая регрессия решает задачу классификации, показывая вероятность того, что данное исходное значение принадлежит к определенному классу. Алгоритм решающего дерева использует иерархическую структуру в виде древовидной модели для принятия решений. Дерево строится путем разбиения данных на подмножества на основе значений признаков с целью классификации, пока не останется только один класс [7]. Стоит отметить, что одно решающее дерево имеет тенденцию к переобучению под конкретную обучающую выборку, поэтому на практике следует использовать композицию решающих деревьев (Random Forest). В основе алгоритма Random Forest лежит использование нескольких решающих деревьев. Оптимизация решающих деревьев под конкретную задачу сводится к перебору признаков и порогов разбиения, чтобы найти лучшее разбиение [8].
Несмотря на то что Random Forest широко используется для построения моделей и может строиться параллельно, на больших данных и при высоком количестве признаков строить глубокие деревья не очень эффективно, так как процесс обучения получается более трудоемким и длительным. Увеличить скорость построения деревьев возможно, ограничив глубину, но в таком случае снижается точность модели. Кроме того, для решения сложных задач может потребоваться большее количество деревьев. Если отказаться от позиции, где каждое дерево строится независимо от всех остальных, и попытаться учитывать «опыт» результатов, полученных при построении прошлых деревьев, то можно более эффективно объединять деревья в композицию, в чем заключается суть метода градиентного бустинга. Градиентный бустинг позволяет строить каждое следующее дерево таким образом, чтобы оно минимизировало ошибку всех предыдущих деревьев. Данный принцип называется «композиция по индукции». Выходным данным отдельных деревьев присваивается вес. Затем неправильным классификациям из первого дерева решений присваивается больший вес, после чего данные передаются в следующее дерево. После многочисленных циклов бустинг объединяет слабые классификаторы в один мощный алгоритм прогнозирования [9].
Градиентный бустинг можно применять не только для решающих деревьев, но также для других алгоритмов. Иными словами, градиентный бустинг представляет собой градиентный спуск в пространстве алгоритмов. В отличие от алгоритма Random Forest, градиентный бустинг легко переобучается на данных. Эффективность бустинга заключается в том, чтобы использовать простые алгоритмы (не обучать долго каждый алгоритм, деревья глубины порядка 5–8) и каждый следующий выбирать так, чтобы минимизировать ошибку. Данная техника в значительной степени приводит к улучшению результатов, и на больших объемах данных градиентный бустинг работает быстрее метода Random Forest [10].
В настоящий момент опубликовано большое количество работ, посвященных разработке предиктивной модели исхода программы ВРТ на основе МО, однако большинство исследований включают работы по анализу прогностической способности моделей, построенных на основании Random Forest. Одно из наиболее крупных исследований в области МО на основании алгоритма Random Forest было опубликовано в 2022 г. В исследование включены 24 730 супружеских пар, проходящих лечение бесплодия методом экстракорпорального оплодотворения (ЭКО)/интрацитоплазматической инъекции сперматозоида в ооцит (ИКСИ). Обучение алгоритма производилось при помощи модели Random Forest и логистической регрессии. В исследовании были определены переменные, в максимальной степени влияющие на прогноз лечения, среди которых наиболее значительный вклад внес протокол овариальной стимуляции, а в качестве метода МО наиболее перспективным зарекомендовал себя Random Forest [11]. Несмотря на положительные результаты, которые показывают алгоритмы на основе Random Forest, данные модели имеют недостатки, ограничивающие их применение и работу.
Цель данного исследования заключается в изучении аналитической обработки клинико-анамнестических и эмбриологических данных пациентов в программе ВРТ различными методами МО; определении точности прогнозирования результата ВРТ с использованием различных алгоритмов и выбора модели МО, которая будет иметь максимальную практическую ценность в отношении наступления беременности.
Материалы и методы
На предыдущем этапе работы совместно с биоинформатиками и специалистами в области МО и ИИ было выполнено пилотное исследование и проанализированы данные клинико-лабораторных обследований и параметры стимулированного цикла в зависимости от эффективности программы ВРТ при помощи трех наиболее широко используемых алгоритмов МО: логистической регрессии, решающего дерева и Random Forest [9]. Согласно полученным результатам, при сравнении трех алгоритмов МО наиболее точный прогноз частоты наступления беременности в программе ВРТ был получен при использовании алгоритма Random Forest. Модель обнаружила наиболее значимые факторы, имеющие важное значение в определении эффективности программы ВРТ: остановка эмбрионов в развитии, триггер финального созревания ооцитов, количество эмбрионов отличного и среднего качества, продолжительность стимуляции, фактор бесплодия, индекс массы тела, уровни фолликулостимулирующего и антимюллерова гормонов (АМГ). Кроме этого, значимость предикторов, которые были определены при помощи алгоритма решающего дерева, была также подтверждена при помощи Random Forest: наличие/отсутствие беременностей в анамнезе, параметры стимулированного цикла, показатели спермограммы в день пункции, количество эмбрионов отличного и хорошего качества, а также качество эмбриона.
В данное исследование ретроспективно были включены 854 супружеские пары в возрасте от 21 до 44 лет, обратившиеся за лечением бесплодия методом ВРТ. От каждой пары было получено письменное добровольное информированное согласие на обработку персональных данных.
Критерии включения в исследование: бесплодие, обусловленное трубно-перитонеальным, мужским или сочетанным фактором, хронической ановуляцией или сниженным овариальным резервом, а также наличие нормального кариотипа супругов, овариальная стимуляция по протоколу с антагонистом гонадотропин-рилизинг-гормона (антГнРГ), стандартный протокол поддержки посттрансферного периода, получение собственных ооцитов в день трансвагинальной пункции (ТВП), перенос 1 эмбриона. Критерии исключения: аномалии строения матки, аномалии кариотипа, использование донорских ооцитов или спермы.
Все пациентки, включенные в исследование, были распределены на 5 групп в зависимости от возраста: 21–24 года (группа 1, n=100), 25–29 лет (группа 2, n=195), 30–34 года (группа 3, n=220), 35–39 лет (группа 4, n=256), 40–44 года (группа 5, n=83).
Пациенткам, включенным в исследование, была проведена овариальная стимуляция по протоколу с антГнРГ со 2-го или 3-го дня менструального цикла. По достижении фолликулами диаметра ≥17 мм пациенткам был назначен триггер финального созревания ооцитов – препарат хорионического гонадотропина (600 пациенток), или, в случае риска возникновения синдрома гиперстимуляции яичников, производилась замена триггера на агонист ГнРГ (171 пациентка), или был назначен двойной триггер финального созревания ооцитов (83 пациентки). Через 35–36 ч после введения триггера овуляции была проведена ТВП с последующим забором ооцитов и оценкой их качества. Оплодотворение полученных ооцитов было выполнено методом ЭКО (5,6%), ИКСИ (81,9%) и физиологического ИКСИ (ПИКСИ) (12,5%). Все этапы культивирования проводили в мультигазовых инкубаторах СООК (Ирландия) в каплях по 25 мкл под маслом (Irvine Sc., USA) на базе отделения вспомогательных технологий в лечении бесплодия им. проф. Б.В. Леонова. На 5-е сутки после оплодотворения осуществлялся перенос эмбриона в полость матки с помощью мягкого катетера Wаllасe (Германия) или Сооk (Австралия). Оставшиеся эмбрионы, подходящие по качеству для дальнейшего применения в криопротоколе, криоконсервировали. Поддержка лютеиновой фазы и дальнейшее ведение посттрансферного периода осуществлялись по стандартной общепринятой методике. На 14-й день после переноса эмбрионов производилась оценка уровня бета-субъединицы хорионического гонадотропина человека (β-ΧГЧ). При положительном результате β-ΧГЧ через 21 день после переноса пациенткам выполнялось ультразвуковое исследование малого таза для диагностики клинической беременности. Дальнейшее ведение беременности осуществлялось индивидуально.
В исследовании были также проанализированы эмбриологические параметры стимулированного цикла: показатели спермограммы в день ТВП (концентрация сперматозоидов, процент прогрессивно-подвижных сперматозоидов, процент непрогрессивных сперматозоидов, неподвижных, процент морфологически здоровых сперматозоидов), количество ооцит-кумулюсных комплексов (ОКК), зрелых ооцитов (MII), количество оплодотворившихся ооцитов (2PN), качество эмбриона, количество бластоцист отличного, хорошего и среднего качества, а также количество эмбрионов, остановившихся в развитии. Кроме этого, была проанализирована частота наступления клинической беременности.
Статистический анализ и алгоритм построения моделей МО
Совместно с экспертами в области МО и ИИ в исследовании были проанализированы входные признаки (51), разбитые на 3 группы:
- бинарные – дискретные переменные, принимающие только два значения;
- категориальные – дискретные переменные, принимающие одно из конечного количества значений и обозначающие принадлежность объекта к какой-то категории;
- вещественные – значения признака из вещественного множества.
Перед этапом моделирования анализируемая выборка была разделена случайным образом на обучающую (train) и тестовую (test) в отношении: train – 70%, test – 30%.
Для моделирования были рассмотрены следующие алгоритмы.
- Логистическая регрессия.
- Решающее дерево.
- Random Forest.
- Градиентный бустинг над решающими деревьями (XGBoost, CatBoost).
Для проведения анализа метрик качества модели были введены критерии precision и recall.
Допустим, что существует два класса и алгоритм, предсказывающий принадлежность каждого объекта к одному из классов; тогда матрица ошибок классификации будет выглядеть, как представлено в таблице 1.
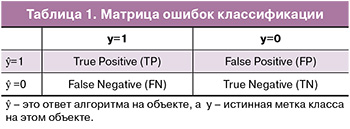
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). Для оценки качества работы модели на каждом из классов по отдельности будем использовать метрики precision и recall.

Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющихся положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм. Именно введение precision не позволяет заносить все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность алгоритма обнаруживать данный класс вообще, а precision – способность отличать этот класс от других классов. Precision и recall не зависят от соотношения классов и потому применимы в условиях несбалансированных выборок.
Существует несколько различных способов объединить precision и recall в агрегированный критерий качества. F1-мера (в общем случае Fβ) – среднее гармоническое precision и recall:

β в данном случае определяет вес точности в метрике, и при β=1 это среднее гармоническое (с множителем 2, чтобы в случае precision=1 и recall=1 иметь F1=1).
F-мера достигает максимума при полноте и точности, равной единице, и близка к нулю, если один из аргументов близок к нулю. Еще одним из способов оценить модель в целом, не привязываясь к конкретному порогу, является AUC-ROC – площадь (Area Under Curve) под кривой ошибок, ограниченная ROC-кривой и осью доли ложных положительных классификаций. Чем выше показатель AUC, тем качественнее классификатор; при этом значение 0,5 демонстрирует непригодность выбранного метода классификации.
Результаты
Для сравнения эффективности каждой модели были использованы метрики качества, отраженные в таблице 2.
Согласно таблице 2 и результатам анализа метрик качества, лучшие результаты демонстрирует модель CatBoost. Стоит отметить, что у модели CatBoost есть еще одно преимущество по сравнению с другими моделями МО. Алгоритм CatBoost работает с категориальными переменными, что дает возможность интерпретации вклада каждого из показателей в итоговый прогноз модели (для остальных моделей категориальные переменные кодируются с помощью метода One-Hot Encoding; таким образом, вместо одного показателя появляется N новых, где N – число категорий, что делает процесс интерпретации немного сложнее) [12].
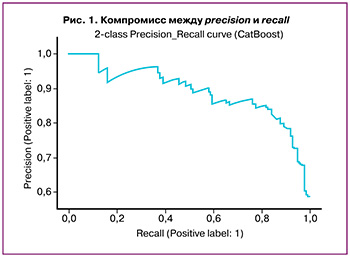
На следующем этапе была построена Precision-Recall кривая, чтобы детальнее проанализировать результаты работы обученной модели. Данная кривая позволяет показать компромисс между precision и recall. Каждое значение оценки классификатора для каждого тестового примера показывает, насколько уверенно классификатор предсказывает положительный или отрицательный класс. Например, согласно рисунку 1, можно видеть, что при 100% полноте точность модели составляет 58%.
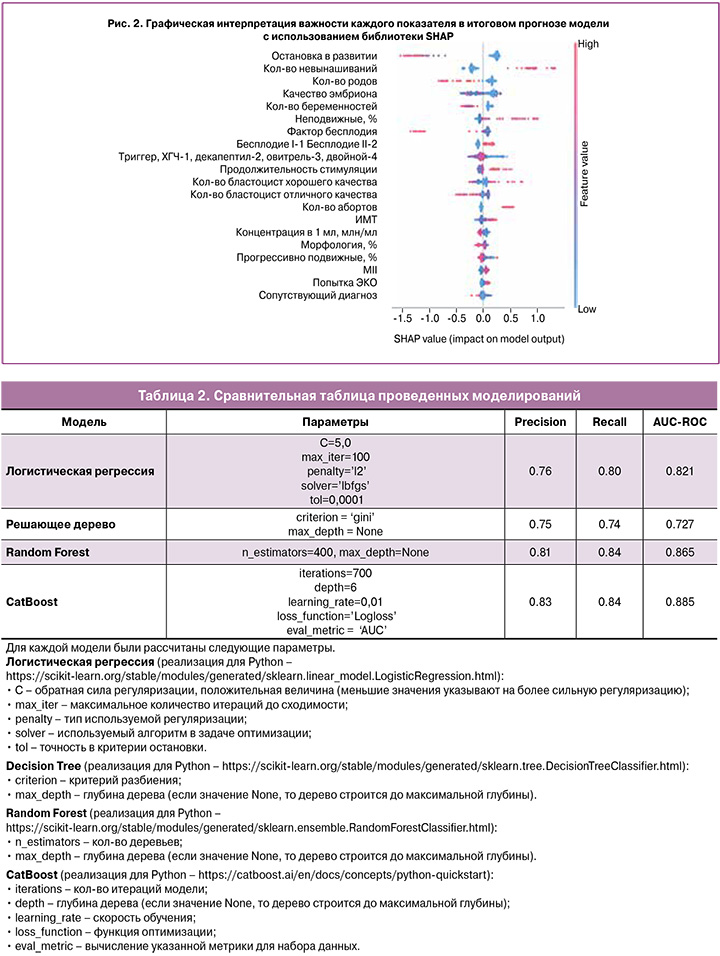
Для интерпретации важности каждого показателя в итоговом прогнозе модели была использована библиотека SHAP (SHapley Additive exPlanations), представленная на рисунке 2. Для оценки важности показателей были рассчитаны значения Шэпли, которые позволяют выявлять все возможные комбинации и варианты, а проанализировав данные, определить, какие факторы на самом деле важны при выборе. Для оценки важности показателя была выполнена оценка предсказаний модели «с» и «без» данного показателя.
Для правильного анализа графика необходимо отметить, что каждая точка является отдельным наблюдением, и чем выше признак по оси Y, тем он более важен в отношении частоты наступления беременности (рис. 2). Значения слева от центральной вертикальной линии – это отрицательный (negative) класс (0), справа – положительный (positive) класс (1); при этом, чем толще линия на графике, тем больше таких точек наблюдения. Цветом обозначены значения соответствующего признака: чем выше признак – тем более красным цветом он обозначен, низкие значения обозначены синим.
Кроме этого, SHAP также позволяет проводить интерпретацию конкретных наблюдений, т.е. получить локальные объяснения для конкретной пары по важности признаков. Рассмотрим пример пациентки старшего репродуктивного возраста, обратившейся за лечением при помощи ВРТ, с первичным бесплодием и уровнем АМГ 0,1 нг/мл. Согласно построенной модели, эффективность программы у данной пациентки низкая, даже без дополнительного анализа показателей спермограммы и значений возраста женщины, так как вклад в финальный прогноз в данном случае вносят только уровень АМГ и наличие/отсутствие беременностей в анамнезе (рис. 3).
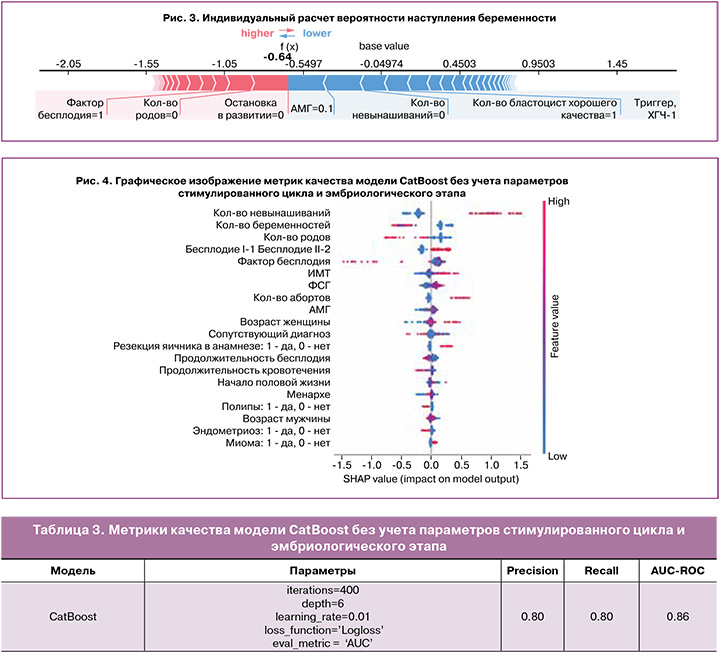
Полученный график показывает, как разные признаки влияют на итоговое предсказание модели. В случае классификации какие-то переменные сдвигают его к классу 0, а какие-то – к 1. Так, если значение Шепли положительное (выделено розовым цветом), то оно смещает предсказание в сторону положительного класса (1, вправо), если негативное (выделено голубым) – отрицательного (0, влево).
На следующем этапе было решено исключить из обучающей выборки показатели стимулированного цикла и эмбриологического этапа для расчета предиктивного показателя эффективности программы ВРТ (исключены: попытка ЭКО, препарат стимуляции, продолжительность стимуляции, триггер финального созревания ооцитов, суммарная доза, тип оплодотворения, показатели спермограммы, количество ОКК, MII, 2PN, качество эмбриона, количество бластоцист отличного, хорошего, среднего качества и количество бластоцист, остановившихся в развитии).
В качестве модели был использован алгоритм CatBoost, результаты представлены в таблице 3.
По сравнению с моделью CatBoost, обученной на всех данных, отмечается лишь незначительное снижение метрик качества: точность снизилась на 0,03, полнота – на 0,04. Графическая интерпретация важности каждого признака изображена на рисунке 4.
Можно сделать вывод, что параметры стимулированного цикла и эмбриологического этапа, безусловно, влияют на наступление клинической беременности, однако их влияние незначительно. С другой стороны, полученные результаты можно объяснить с точки зрения сильной взаимосвязи клинико-анамнестических параметров и соответствующих показателей стимулированного цикла и эмбриологического этапа, требующих дальнейшего изучения.
Таким образом, полученная система показала, что для разных пациентов вклад тех или иных показателей в окончательный прогноз может быть разным; соответственно, и наиболее значимые факторы, определяющие итоговый прогноз, могут различаться у разных супружеских пар. Чтобы окончательно убедиться в верности полученных модельных оценок, необходимо в первую очередь расширить обучающую выборку теми случаями, которые на данной выборке встречаются реже. Однако уже сейчас можно сделать вывод, что модель выдает достаточно высокие метрики, решая задачу определения вероятности наступления клинической беременности.
Обсуждение
В настоящее время идет активное внедрение методов МО в медицинские информационные системы. В первую очередь это связано с необходимостью анализа большого объема информации о пациентах, а также прогнозирования результата лечения [13]. В данной работе в пилотном исследовании были проанализированы три алгоритма МО: логистическая регрессия, дерево решений и Random Forest. Согласно полученным метрикам, наиболее точной моделью в отношении частоты наступления беременности в программе ВРТ оказался алгоритм, построенный при помощи Random Forest [9]. Далее полученные результаты были проанализированы с использованием градиентного бустинга над решающими деревьями. Результаты исследования показали, что наиболее точные модели для решения задач классификации основаны на использовании алгоритмов Random Forest и градиентного бустинга над решающими деревьями. На их долю приходится более 70% всех разработанных моделей. Эти алгоритмы достаточно универсальны; зачастую показывают более высокое качество, после обучения имеется возможность определить важность каждого признака (его вклад в прогностическую силу модели) [11]. Базовый же алгоритм по классификации, с которым всегда происходит сравнение всех разрабатываемых моделей, – это логистическая регрессия. Ее особенностями являются простота реализации, скорость работы, а также интерпретируемость результатов (логистическая регрессия оценивает вероятность наступления события, а также интерпретирует результаты на основе важности каждого признака). В ходе анализа была выбрана реализация CatBoost, т.к. эта модель предоставляет удобный интерфейс при работе с категориальными переменными (для ускорения работы может быть использован один из двух аналогов – XGBoost или LightGBM; все эти реализации показывают сравнимые результаты) [12].
Одним из наиболее мощных инструментов для МО являются искусственные нейронные сети [14]. Однако, несмотря на превосходство точности прогноза в отдельных случаях и универсальность использования на различных данных, они имеют два существенных недостатка: невозможность анализа работы алгоритма и ресурсоемкость процесса обучения [15]. Исходя из объема обучающего датасета и типа собранных данных, использование нейронных сетей в данном случае нецелесообразно. В связи с этим был выбран метод градиентного бустинга над решающими деревьями, представленный библиотекой XGBoost.
В основе CatBoost лежит алгоритм градиентного бустинга деревьев решений. Градиентный бустинг – это техника МО для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений. Обучение ансамбля проводится последовательно: на каждой итерации вычисляются отклонения предсказаний уже обученного ансамбля на обучающей выборке [16]. Следующая модель, которая будет добавлена в ансамбль, будет предсказывать эти отклонения. Таким образом, добавив предсказания нового дерева к предсказаниям обученного ансамбля, можно уменьшить среднее отклонение модели, которое является таргетом оптимизационной задачи. Новые деревья добавляются в ансамбль до тех пор, пока ошибка уменьшается либо пока не выполняется одно из правил «ранней остановки». Чаще всего на практике CatBoost показывает более высокое качество; однако данный алгоритм имеет достаточно много параметров, и поиск оптимальных характеристик может занять некоторое время.
Еще один метод, проанализированный в данном исследовании, Random forest, использует ансамбль деревьев решений, созданных на случайно разделенном датасете [17]. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака. Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс [18].
Данный метод обладает рядом преимуществ.
- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки.
- Высокая параллелизуемость и масштабируемость.
Для построения данного алгоритма использовалась реализация модели для Python из библиотеки scikit-learn https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html. Тем не менее среди недостатков модели следует выделить потенциальный недостаток – для категориальных переменных с большим количеством значений метод склонен считать такие переменные более важными. Частичное перемешивание значений в этом случае может снижать влияние этого эффекта [10]. Из групп коррелирующих параметров, важность которых оказывается одинаковой, выбираются меньшие по численности группы. Кроме этого, Random Forest достаточно медленный, так как для работы алгоритм использует множество деревьев: каждому дереву в лесу передаются одни и те же входные данные, на основании которых оно должно вернуть свое предсказание. После чего также происходит голосование на полученных прогнозах. Модель Random Forest сложнее интерпретировать по сравнению с деревом решений, где можно легко определить результат, следуя по пути в дереве [19]. Алгоритм CatBoost не имеет данных ограничений и может быть использован для различных задач классификации и работы с большими данными. Стоит отметить, что полученные результаты показали, что максимальные значения precision и recall были получены именно для этой модели. Алгоритм, построенный c использованием CatBoost, показал, что максимальное влияние на эффективность программы ЭКО оказывает наличие/отсутствие беременности в анамнезе/количество невынашиваний/родов, а также качество эмбриона и количество эмбрионов, остановившихся в развитии. Кроме этого, на частоту наступления беременности оказывают влияние триггер финального созревания ооцитов, продолжительность стимуляции, количество бластоцист хорошего и отличного качества, показатели спермограммы в день пункции, а также количество ооцитов МII.
В исследованиях в области репродуктивной медицины использование алгоритма CatBoost зарекомендовало себя как высокоэффективный и удобный метод прогнозирования результата и оптимизации лечения. В исследовании Tikhaeva K. et al. был проанализирован прогнозируемый ответ на овариальную стимуляцию в протоколах ВРТ с использованием градиентного бустинга, линейной регрессии, алгоритма решающего дерева и Random Forest. Наиболее точная модель была получена с использованием градиентного бустинга и Random Forest. В модель были включены клинико-анамнестические данные пациентов, показатели овариального резерва, параметры стимулированного цикла, количество полученных ооцитов в предыдущих программах ВРТ. Алгоритм прогнозировал ответ на овариальную стимуляцию с точностью 82,3% [20].
Одно из наиболее крупных исследований в отношении прогнозирования эффективности программы ВРТ с использованием различных методов МО было опубликовано в 2022 г. Цель данного исследования заключалась в определении наиболее точной модели МО для прогнозирования эффективности ВРТ, а также наиболее значимых факторов, влияющих на прогноз. В исследовании была построена модель логистической регрессии, дерево решений, наивный байесовский классификатор, Random Forest, метод опорных векторов, искусственные нейронные сети, градиентный бустинг над решающими деревьями. Результаты оценивались с помощью показателей производительности (F1-мера, специфичность, точность и площадь под кривой). Наиболее точными в отношении прогнозирования частоты имплантации в программе ВРТ были модели, полученные с использованием алгоритма Random Forest и градиентного бустинга над решающими деревьями (Super-learner). Кроме того, полученные результаты показали, что максимальное значение в прогноз результата программы ВРТ вносят возраст матери, день переноса эмбрионов, суммарная доза гонадотропинов и концентрация эстрадиола в день назначения триггера финального созревания ооцитов [21].
Базовый же алгоритм по классификации, с которым всегда происходит сравнение всех разрабатываемых моделей, – это логистическая регрессия. Ее особенностями являются простота реализации, скорость работы, а также интерпретируемость результатов. В исследовании Hansen K.R. et al. была использована логистическая регрессия для анализа частоты имплантации, клинической беременности и частоты живорождений у 900 пар с бесплодием неясного генеза. Значения AUC модели прогнозирования частоты имплантации, клинической беременности и живорождения составили 0,66, 0,64 и 0,65 соответственно [22]. Meijerink A.M. et al. разработали модель прогнозирования на основе многомерной логистической регрессии с использованием набора данных, полученных от 289 пар после проведения TESE. AUC модели прогнозирования логистической регрессии составляла 0,67 [23]. Таким образом, результаты наиболее значимых и крупных исследований по изучению точности логистической регрессии показали, что эффективность модели не превышает в среднем 0,65, несмотря на репрезентативную выборку пациентов.
По сравнению с логистической регрессией алгоритмы МО являются более чувствительными и более точными методами проверки, для которых ограничения традиционной регрессии применимы в меньшей степени. В репродуктивной медицине алгоритмы МО также использовались в нескольких исследованиях. Blank C. et al. ретроспективно включили данные, собранные от 1052 супружеских пар, после проведения программы ЭКО/ИКСИ и переноса эмбриона. Набор данных содержал 32 переменные, включая непрерывные переменные (возраст мужчины и женщины, уровень АМГ), категориальные переменные (протоколы стимуляции) и дискретные переменные (количество ооцитов). Для прогнозирования имплантации после переноса бластоцисты алгоритм случайного леса показал лучшую прогностическую эффективность, чем логистическая регрессия с точки зрения AUC (0,74 для случайного леса и 0,66 для логистической регрессии) [24]. В исследовании Qiu J. et al. были проанализированы такие переменные, как возраст, АМГ, продолжительность бесплодия, индекс массы тела, количество предыдущих родов, невынашиваний, абортов, фактор бесплодия у 7188 женщин после первой программы ЭКО и переноса эмбриона. Среди факторов, влияющих на частоту наступления беременности, максимальное значение в финальный прогноз вносили наличие/отсутствие беременностей в анамнезе/родов/невынашиваний и т.д., что согласуется с полученными в данной работе результатами [25]. Следует обратить внимание на то, что одним из наиболее важных признаков в отношении частоты наступления беременности, согласно результатам данного исследования, оказалось «наличие/отсутствие беременности/невынашиваний/родов в анамнезе». Полученные данные вносят значительный вклад в дальнейшее изучение влияния различных предикторов на эффективность программ ВРТ. Наличие первичного бесплодия как фактора, который негативно влияет на наступление беременности в программе ВРТ, отражает более сложные молекулярно-биологические маркеры рецептивности и восприимчивости эндометрия, а также имплантационного потенциала получаемого эмбриона, требующие дальнейшего изучения. Кроме этого, в исследовании сравнивалась эффективность моделей МО, включая метод опорных векторов, Random Forest и градиентный бустинг (XGBoost), которые в значительной степени превзошли традиционную логистическую регрессию в персонализированном прогнозировании частоты наступления беременности. Среди методов МО максимально точными оказались алгоритмы бустинга и алгоритм случайного леса, прогнозирующие наступление беременности с 73% точностью [25].
Обращает на себя внимание, что среди факторов, которые вносят максимальное значение в финальный прогноз, из всех показателей спермограммы в день пункции наиболее важным оказалась концентрация сперматозоидов в 1 мл, что подтверждает необходимость оптимизации выбора максимально качественного сперматозоида для оплодотворения. Высокая концентрация сперматозоидов в эякуляте дает эмбриологу возможность селекции наиболее качественного сперматозоида. В исследовании Rodrigo L. et al. единственным фактором, используемым при оценке качества эякулята, который вносил максимальное значение в хромосомный статус эмбриона, была именно концентрация сперматозоидов [26]. В исследовании Harris A.L. et al. было показано, что на частоту оплодотворения влияют больше всего концентрация сперматозоидов и их подвижность, что еще раз подтверждает необходимость дополнительной оптимизации алгоритма подготовки мужчин к программам ВРТ и оценки эффективности использованного лечения [27].
Самым важным показателем в отношении частоты наступления клинической беременности оказался параметр «количество эмбрионов, остановившихся в развитии». Полученные данные подтверждают, что в имплантацию эмбриона в эндометрий в бóльшей степени вносит вклад именно эмбрион; при этом качество эмбриона зависит от исходного качества гамет. Вероятно, качество эмбриона коррелирует с количеством эмбрионов, остановившихся в развитии. Данный маркер может выступать как вспомогательный маркер оценки хромосомного набора получаемого эмбриона, так как чем больше эмбрионов остановилось в развитии у пациентов в программе ВРТ, тем менее вероятно наступит беременность, несмотря на наличие эмбриона хорошего/отличного качества. Работа McCoy R.C. et al. показывает, что у эмбрионов, остановившихся в развитии, арест происходит за счет мейотических и митотических нарушений делений клетки, и пригодные для переноса эмбрионы, вероятно, также могут носить аномальный набор хромосом [28].
Таким образом, полученные результаты отражают необходимость дальнейшего изучения влияния определенных факторов на частоту наступления беременности. В рамках данного исследования было собрано более 500 образцов фолликулярной жидкости, семенной плазмы, сперматозоидов и среды культивирования эмбриона у пациентов, проходящих лечение бесплодия методом ВРТ согласно интегрированной системе хранения биологических образцов для комплексной оценки эффективности лечения и оптимизации выбора наиболее качественного эмбриона для переноса [29]. Созданный программный продукт позволит в будущем повысить частоту наступления беременности не только за счет оптимизации корригируемых факторов и селекции наиболее перспективного эмбриона для переноса с использованием метаболомного профилирования различных биологических образцов, но и с помощью определения максимально перспективной группы пациентов для более эффективного клинико-экономического распределения бюджета.
Заключение
Несмотря на значительные достижения в отношении создания систем на основе регрессионного анализа, их прогностическая точность остается ограниченной. Таким образом, для повышения качества модели требуются более качественные математические модели с интегральным подходом к решению задачи, а также дополнительные маркеры, позволяющие улучшить точность диагностики. К таким маркерам следует отнести различные инновационные способы оценки качества эмбриона и половых гамет, дополняющие прогностическую ценность данных анамнеза супружеской пары, параметров стимулированного цикла, эмбриологического этапа, а также стандартных способов оценки качества ооцитов и эякулята. Построение модели, включающей не только данные анамнеза супружеской пары, но и молекулярные маркеры, с использованием сложных математических систем позволит не только определить наиболее точно максимально перспективные группы пациентов для проведения программы ЭКО, но и оптимизировать лечение в данных группах, а также повысить эффективность программ ВРТ за счет селекции максимально качественного эмбриона для переноса. Стоит подчеркнуть, что на этапе создания программного продукта необходимо обязательное участие биоинформатиков и математиков, специализирующихся в области МО и ИИ; тем не менее, в будущем использование готовой программы может осуществляться любым врачом без специальной подготовки за счет простого и интуитивно понятного интерфейса.


