
Ишемическая болезнь сердца (ИБС) — ведущая причина заболеваемости и смертности в России и других экономически развитых странах c 1900 г., за исключением 1918 г., когда была пандемия гриппа. Прогнозируется, что к 2020 г. ИБС будет ведущей причиной смертности во всех странах мира [1]. Наиболее эффективный способ снизить заболеваемость ИБС — проводить первичную профилактику. Термин «фактор риска» (ФР) был предложен William Kannel — одним из пионеров Фрамингемского исследования, в 1961 г. [2]. Смысл этого термина заключался не только в выявлении причины, но и в прогнозировании исходов заболевания. Прогностическая значимость отдельных ФР в качестве скрининговых тестов для ИБС низкая. Почти в 50% случаев инфаркт миокарда (ИМ) развивается у пациентов с нормальным содержанием холестерина в сыворотке, и приблизительно у 20% пациентов с коронарными осложнениями нет традиционных ФР развития ИБС [3, 4]. Ограничения отдельных ФР привели к созданию системы интегральной оценки риска — алгоритма Фрамингем. Прогресс в изучении ФР за последние 50 лет привел к ощутимому снижению смертности от ИБС. Однако заболеваемость ИБС сохраняется на высоком уровне, и это ставит под сомнение эффективность действующих профилактических стратегий [5]. В результате растет интерес к новым стратегиям скрининга.
Атеросклероз — результат комплексного взаимодействия генетических и средовых факторов. Изучение генов одновременно с корригируемыми ФР развития ИБС влияет на стратификацию риска и позволяет персонализировать стратегии профилактики. Изучение генетического риска при комплексных заболеваниях — сложная проблема ввиду полигенной природы заболевания и незначительного вклада отдельных генов, что служит объяснением противоречивых результатов исследований [6, 7].
С увеличением количества исследованных генов растет число их возможных комбинаций, что значительно затрудняет их изучение методами традиционной статистики. Кроме того, для стратификации риска необходима интеграция в прогностическую модель информации о генетических и фенотипических признаках. Оптимальным для стратификации риска является создание модели, учитывающей генетический риск и фенотипические проявления одновременно, что значительно улучшит ее качество. Любая статистическая модель использует понятия «случайных событий», в то время как взаимосвязи между различными параметрами исследуемых объектов или явлений являются детерминированными. Применение статистических методов подразумевает наличие определенного числа наблюдений для обоснованности конечного результата. Это означает, что в ситуациях анализа в принципе непредставительных данных или на этапах начала накопления данных статистические подходы становятся неэффективными как средство анализа и прогноза. Многочисленность анализируемых факторов, приближенность оценки результатов обусловливает необходимость привлечения математических методов и компьютерных средств, которые позволили бы анализировать слабо формализованный материал и результативно использовать его для поддержки принятия решений о диагностике и профилактике у конкретного пациента. Перспективным представляется применение методов математической теории распознавания по прецедентам. Для данных подходов не требуются математические модели заболеваний, а в качестве исходной информации используются лишь признаковые описания прецедентов.
Материал и методы
Обследован 131 больной ИБС, включая 85 (64,9%) мужчин и 46 (35,1%) женщин, средний возраст которых составил 60,5±11,9 года. Это пациенты, перенесшие острые коронарные осложнения. Распределение больных по формам ИБС было следующим: ИМ — 100 (76%), нестабильная стенокардия — 31 (24%). Из них 13% перенесли стентирование и аортокоронарное шунтирование. Диагноз ИМ у всех подтвержден типичными изменениями на электрокардиограмме, повышением уровня ферментов (креатинфосфокиназы, тропонина Т), нарушениями локальной сократимости миокарда по данным эхокардиографии (ЭхоКГ). Диагноз ИБС у всех верифицирован при коронарографии (выявлен стеноз ≥75%, по крайней мере, в одной из основных коронарных артерий). Контрольная группа состояла из 159 человек: 90 (56,6%) мужчин и 69 (43,4%) женщин в возрасте от 36 до 79 лет (средний возраст 54,3±8,21 года). В контрольную группу вошли пациенты, обратившиеся в Медицинский центр Банка России для проведения диспансерного обследования. У них отсутствовали в анамнезе ИБС, ишемический или геморрагический инсульт, а также другие тромбоэмболические или геморрагические осложнения. Для исключения безболевой ишемии миокарда пациентам выполняли электрокардиогра-фию, ЭхоКГ, велоэргометрическую пробу.
У пациентов с ИБС и в контрольной группе оценивали следующие ФР: артериальная гипертензия (систолическое артериальное давление — АД ≥140 мм рт.ст. и/или диастолическое АД ≥90 мм рт.ст.), гиперхолестеринемия (>5,2 ммоль/л и/или прием гиполипидемического препарата), сахарный диабет (глюкоза натощак ≥7 ммоль/л, гликированный гемоглобин ≥6,5% или прием сахароснижающего препарата), ожирение (индекс массы тела ≥30 кг/м2) и курение. Семейный анамнез расценивали как отягощенный при наличии у родственников первой степени родства ИМ, инсультов, случаев смерти от сердечно-сосудистых заболеваний в возрасте моложе 55 лет для мужчин и 65 лет для женщин или при наличии более одного родственника с ИБС, особенно женского пола [8].
Выбор полиморфных вариантов генов. Для исследования выбрали 27 генов-кандидатов, которые согласно международным базам данных ассоциируются с ИБС. Учитывали расположение генов в экзонах или промоторных участках ДНК, что предполагает изменение функции или экспрессии кодируемого белка. Изучили 29 полиморфизмов в 27 генах, которые имеют отношение к различным звеньям патогенеза ИБС:
- нарушения липидного обмена: ApoE(ε2, ε3, ε4), ApоCIII (S1/S2), PON1 (Gln192Arg);
- эндотелиальная дисфункция и воспаление: ecNOS (4/5), NOS1(n10/n14) TNF-α (-238G>A,-308G>A), FGB (455G>A);
- артериальная гипертензия: AGT (М235Т), ACE (I/D), AGTR1 (1166A>C), AGTR2 (3123 C>A), BKR2 (-58 T>C), REN (19-83G>A), ADRB1 (R389G), ADRB2 (48A>G и 81C>G);
- тромбообразование и нарушение агрегации тромбоцитов: FV (R506Q), FII (20210G>A), PAI-1 (4G/5G), PLAT(I/D), GPIIIα (196T>C), FGB (455G>A);
- гипергомоцистеинемия: MTHFR (677С>Т), MTRR (66A>G);
- инсулинорезистентность: PPAR-α(2528G>C), PPAR-γ(34C>G), PPAR-δ (+294T>C), UCP2 (G866A), DQB1 (201/302).
Образцы венозной крови брали натощак в количестве 10 мл в стандартные одноразовые пробирки, содержащие EDTA KE/2,7 мл. В работе использовали образцы ДНК, выделенные из лимфоцитов периферической крови. Полиморфизмы генов исследовали методом полимеразной цепной реакции. Генетические исследования выполняли в лаборатории пренатальной диагностики наследственных болезней Института акушерства и гинекологии им. Д.О. Отта (Санкт-Петербург).
Биохимические исследования. Лабораторные ФР развития ИБС оценивали ретроспективно по материалам компьютерной базы данных до установления диагноза ИБС. Пациенты не принимали антикоагулянты.
Липидный состав, липопротеин (а), высокочувствительный С-реактивный белок определяли в сыворотке крови турбодиметрическим методом на автоматическом анализаторе ADVIA 1650 (Bayer). Уровень гомоцистеина в сыворотке определяли на автоматическом иммунохемилюминесцентном анализаторе Centaur (Bayer). Для определения D-димера использовали фотометрическую регистрацию агглютинации латексных частиц на автоматическом анализаторе Sysmex CA-1500 (Dade Benring). Фибриноген определяли по скорости образования сгустка при добавлении избытка тромбина к разведенной плазме (метод Клауса) на автоматическом анализаторе Sysmex CA-1500 (Dade Benring).
Инструментальные исследования. Дуплексное сканирование брахиоцефальных артерий выполняли на приборе Logic 9 (GE) с использованием мультичастотного линейного ультразвукового датчика 10L. Толщину комплекса интима—медиа измеряли по стандартному протоколу на 3 уровнях билатерально: в области бифуркации общей сонной артерии, на 1 см ниже бифуркации, а также на внутренней сонной артерии согласно методике Pignoli [9]. Степень стеноза оценивали при эксцентрических бляшках — по диаметру внутреннего просвета артерии, при полуциркулярных и циркулярных бляшках — по площади. Мультиспиральную компьютерную томографию сердца выполняли на компьютерном томографе Light Speed (GE) по следующему протоколу исследования: толщина среза 2,5 мм в сегментарном режиме при задержке дыхания на вдохе и частоте сердечных сокращений 60—80 уд/мин. Кальциевый индекс рассчитывали на рабочей станции AW 4.1 (GE). Для количественной оценки использовали шкалу Agatston. Общий кальциевый индекс — сумма показателей, полученных при анализе 4 основных коронарных артерий, в норме равен 0. ЭхоКГ выполняли широкополосным фазированным датчиком на ультразвуковом приборе iE33 (Philips) по стандартному протоколу. Гипертрофию левого желудочка оценивали из парастернального доступа по длинной оси. Измеряли толщину межжелудочковой перегородки и задней стенки в средней трети левого желудочка в М-режиме в диастолу. Учитывали максимальное значение. Гипертрофию левого желудочка констатировали при толщине стенки >11 мм.
Анализ данных методами теории распознавания. Полученные данные анализировали при помощи системы «РАСПОЗНАВАНИЕ» [10, 11]. Она позволяет по обучающей выборке построить оптимальные алгоритмы для автоматической классификации (прогноза) состояний произвольных новых пациентов по их признаковым описаниям. В процессе построения алгоритма классификации (обучения) выявляются причинно-следственные связи между признаками и исходами, оцениваются ФР, находятся типичные ситуации, определяются другие, прежде всего качественные, характеристики задачи прогноза. В настоящей работе приводятся начальные результаты исследования по задаче прогнозирования ИБС по результатам комплексного обследования. Задача прогноза ставится как задача распознавания между двумя классами: класс К1образуют признаковые описания пациентов, у которых не было ИБС, класс К2 — пациенты, страдающие ИБС (в последнем случае признаковые описания формировались до развития заболевания). Результатом прогноза ИБС для нового пациента является оценка его предрасположенности к данному заболеванию (бинарная или числовая оценка). Следует отметить, что отделимость классов изначально отсутствует в силу формального включения К1⊇ К2 (класс К2 является подмножеством К1). Если у пациента не было ИБС, то не исключено, что это заболевание не разовьется в скором будущем. Тем не менее можно предполагать, что плотности распределения объектов каждого из классов будут заметно выше в различных областях пространства признаковых описаний, а это позволяет использовать идеи частичной отделимости и надеяться в итоге на положительные результаты. Для решения задач прогноза использовали различные подходы и алгоритмы теории распознавания по прецедентам:
— статистические алгоритмы распознавания (метод k-ближайших соседей, линейный дискриминант Фишера);
— алгоритмы распознавания, основанные на построении разделяющих поверхностей (линейная машина, метод опорных векторов);
— логические методы распознавания (тестовый алгоритм [12], вычисление оценок по системам логических закономерностей [11, 13], бинарные решающие деревья [14]);
— распознавание коллективами алгоритмов.
Для всех моделей распознавания могут быть получены оценки качества обучающей информации, оценки степени принадлежности объекта к классу. Как правило, каждый подход имеет свои «предпочтения». Статистические алгоритмы наиболее эффективны в случаях представительных выборок, малого числа признаков и их высокой информативности. Методы, основанные на принципе разделения, «предпочитают» выполнение гипотезы «компактности» классов и числовые признаки. Несомненным достоинством логических методов является их эффективность в случаях разнотипных (качественных/числовых) признаков, большого их количества, малых обучающих выборок. Какой подход или алгоритм является предпочтительным или наилучшим для конкретной задачи, устанавливается численным экспериментом. При этом «угадать» заранее метод-фаворит для новой практической задачи (без проведения предварительных экспериментов) сложно.
Альтернативой выявлению и практическому использованию одного метода является решение задачи распознавания коллективом распознающих алгоритмов, когда задача решается в два этапа. Сначала задача решается независимо друг от друга всеми или частью из имеющихся алгоритмов. По полученным решениям вычисляется окончательное «коллективное» решение. Данный подход позволяет надеяться, что при синтезе коллективного решения ошибки отдельных алгоритмов будут компенсироваться правильными ответами других алгоритмов. Данная двухэтапная схема позволяет эффективно решать задачи в автоматическом режиме, когда на первом уровне «неквалифицированным» пользователем находятся удовлетворительные решения-алгоритмы, а точность прогноза обеспечивается коррекцией полученных решений [10, 15, 16]. В настоящем исследовании особая роль отводилась логическим методам распознавания, прежде всего алгоритмам голосования по системам «логических закономерностей» (ЛЗ) [14, 17].
В исходную информацию о каждом пациенте включали следующие параметры — традиционные ФР, лабораторные показатели, результаты инструментального обследования, генетические маркеры. Генотип оценивали в виде двух моделей: доминантной (комбинация вариантной гомозиготы и гетерозиготы по сравнению с нормальной гомозиготой) и рецессивной (вариантная гомозигота по сравнению с комбинацией нормальной гомозиготы с гетерозиготой). Для каждого пациента рассчитывали индивидуальный генетический индекс (ГИ), представляющий собой суммарное количество имеющихся полиморфных вариантов + семейный анамнез. Таким образом, для каждой группы (пациенты с ИБС и контрольная группа) была сформирована база клинических данных по результатам обследования. Разработке непосредственно моделей прогнозов предшествовал медико-статистический анализ данных, выполненный с помощью компьютерной программы SAS JMP7 by SAS Institute Inc. (Cary, NC, USA).
Результаты и обсуждение
На рисунке (см. цветную вклейку) приведена визуализация 290 объектов таблицы обучения — отображение исходных признаковых описаний объектов размерности 38 на плоскость, с максимальным сохранением метрических отношений между объектами в признаковом пространстве. Синие точки соответствуют объектам первого класса, зеленые — второго. Визуализация соответствует априорным ожиданиям: классы пересекаются, а граница между ними является «размытой».
Общая двухэтапная схема анализа и прогноза состояла в следующем. На первом этапе для заданной таблицы обучения применяли метод голосования по логическим закономерностям (метод ЛЗ) для выделения информативной подсистемы признаков. Использовали основную процедуру: «Вычисляются ЛЗ классов и оценивается в режиме скользящего контроля точность прогноза методом ЛЗ. Вычисляются оценки информативности всех признаков и исключаются признаки наименее информативные». Основную процедуру повторяли до достижения такой подсистемы признаков, сокращение которой ухудшает точность распознавания относительно исходной на заданный порог.
На первом этапе были выявлены признаки, которые продемонстрировали недостаточную информативность и отсутствие влияния на прогноз. В результате была сформирована таблица обучения, в которую вошли наиболее информативные показатели, представленные в табл. 1. Из дальнейшего рассмотрения исключали генотипы, которые имели близкие к нулевым оценки информативности по мнению метода «логические закономерности» и не имели содержательного толкования. На основании проведенного анализа для расчета ГИ из 29 изученных полиморфизмов были отобраны полиморфные маркеры, перечисленные в табл. 1.
Таблица 1. Группы признаков и их состав.
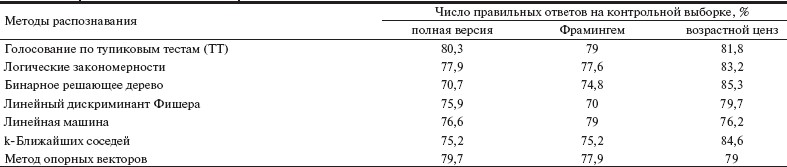
На втором этапе для найденной системы информативных признаков в рамках различных отмеченных выше подходов решались задачи обучения с оценкой их точности в режиме скользящего контроля. С целью оптимизации прогностических маркеров мы проанализировали несколько версий изучаемых показателей. Полная версия представлена в табл. 2 (41 признак). Во второй версии мы объединили традиционные ФР в соответствии с алгоритмом Фрамингем, уменьшив таким образом количество изучаемых признаков до 26. Результаты оказались сопоставимыми с исходными данными (см. табл. 2).
Таблица 2. Прогноз по отдельным алгоритмам.
Затем мы проанализировали влияние пола, возраста и сахарного диабета (СД) на качество прогноза. Мы изучали отдельно выборку, состоящую из мужчин, женщин, пациентов без СД, и не получили существенных различий в качестве прогноза с использованием различных математических алгоритмов. Отдельно мы проанализировали пациентов молодого возраста (мужчины <55 лет, женщины <65 лет) и отметили улучшение качества прогноза в этой группе. Это вполне объяснимо, так как 16 из изучаемых показателей имеют отношение к генетическим маркерам. Изучение наследственной предрасположенности к развитию ИБС более актуально у молодых пациентов. Результаты выполненного анализа представлены в табл. 2. Проанализировав полученные данные, мы пришли к выводу, что большинство ошибок прогноза на нашей выборке связано с тем, что многие пациенты в контрольной группе имели так называемые эквиваленты ИБС. К ним в соответствии с последней редакцией руководства АТР III [2] относятся клинические проявления атеросклероза внекоронарной локализации: атеросклероз артерий нижних конечностей, аневризма брюшного отдела аорты, атеросклероз брахиоцефальных артерий (транзиторные ишемические атаки и/или ишемический инсульт и/или обструкция более 50% просвета сонных артерий), СД или по крайней мере 2 ФР с 10-летним риском развития коронарных осложнений >20%. Для повышения точности прогноза мы переклассифицировали больных с учетом этих критериев, что позволило значительно улучшить качество прогноза. В табл. 3 представлены результаты анализа с использованием различных систем признаков.
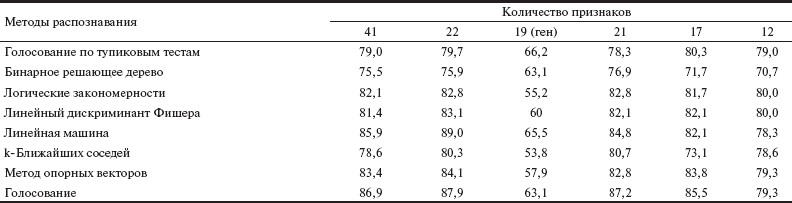
Таблица 3. Точность прогноза различных методов распознавания.
В первом столбце представлены результаты оценки точности прогноза по системе из 41 признака (22 «базовых» и 19 «генетических»). Второй столбец соответствует базовым признакам, третий — только генетическим. В столбцах 4—6 представлены подсистемы из 21, 17 и 12 признаков, полученные из исходных 41 с использованием первого этапа сокращения признаков (см. выше). Сравнение данных позволяет выявить, что результаты прогноза по одним базовым 22 признакам немного превосходят результаты по всем 41 признаку. Это объясняется тем, что базовые признаки сами образуют достаточно информативную подсистему признаков (что подтверждается, прежде всего, методом «линейная машина»). Добавление к ним большого числа генетических признаков, информативными из которых является лишь малая часть, почти в 2 раза повышает размерность признаковых описаний пациентов. В результате усложнение задачи обучения оказывает несколько больший негатив в точность прогноза, чем польза от некоторых генетических признаков. Данные, представленные в третьем столбце, показывают, что прогноз по одним генетическим параметрам пациентов фактически невозможен. Тем не менее 2 генетических признака входят в информативную подсистему из 12 признаков, что свидетельствует о перспективности исследования их влияния с использованием расширенных и уточненных обучающих выборок. Отметим, что если ввести «отказ от распознавания» в ситуациях, когда мнения алгоритмов разделяются как 3:4 или 4:3, то получим (например, по эксперименту № 6) 42 ошибки при 27 отказах на общей выборке в 290 объектов, что составляет 76,2% правильных ответов и 14,5% ошибок при 9,3% отказов от прогноза.
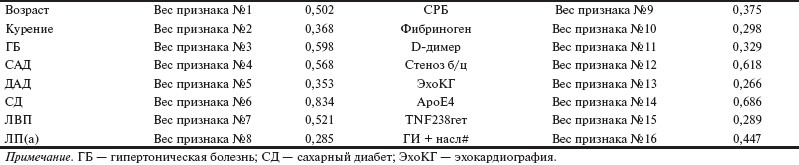
Таблица 4. Подсистема информативных 12 признаков и их веса.
В табл. 4 приведены веса системы из 12 признаков. Обращает внимание, что в этом наборе признаков сохранилось 2 генетических маркера. Один из них — ГИ, представляющий собой суммарное количество имеющихся полиморфизмов + семейный анамнез. Последующая серия экспериментов проведена также с целью выделения информативной подсистемы признаков, но была реализована другая идея. После использования метода ЛЗ на исходной выборке из 290 объектов были удалены объекты, на которых были совершены «грубые ошибки» (оценка за ложный класс превосходит оценку за истинный в 5 раз и более), а также объекты, у которых оценка за каждый класс была менее 0,1. Удаленные объекты можно рассматривать как ошибочные для соответствующего класса или не типичные для обучающей выборки. После удаления 5,5% объектов сокращенная выборка из 274 объектов представляет более качественное описание выборки, что позволило получить более точные оценки важности признаков методом ЛЗ. Было проведено 5 экспериментов при различных значениях управляющих параметров, по результатам которых была сформирована подсистема из 16 признаков. Признак считался информативным, если его вес в каждом эксперименте был не ниже 0,2 (веса признаков приведены в табл. 5).
Таблица 5. Подсистема информативных 16 признаков в эксперименте с сокращенной выборкой.
На оставшейся группе из 16 признаков были проведены эксперименты по распознаванию на всей исходной выборке в 290 объектов. Результаты показывают, что для данной системы из 16 признаков можно построить алгоритм, не уступающий по своей прогностической значимости представленным выше. Точность метода «линейная машина» составила 89%, голосования — 87,2%. Удаление генетических признаков из данной системы приводит к снижению точности распознавания. Внедрение компьютерных систем делает реальным перевод на качественно новый уровень системы разработки методик прогнозирования, основанных на современных математических методах анализа данных и распознавания, и создает предпосылки для внедрения сложных прогностических алгоритмов в широкую клиническую практику.
Прогноз теряет смысл, если на его основе не принимаются эффективные решения. Вместе с тем прогноз является лишь одним из компонентов многоэтапного процесса принятия решений. Для распространенных заболеваний, таких как ИБС, стратификация риска имеет большое клиническое значение. Количественная оценка риска поможет персонализировать профилактические стратегии, и возможно, позволит исключить пациентов с низким риском из скрининговых программ, а также избежать ненужных вмешательств, оптимизируя соотношение риска и пользы.
С учетом ограниченного количества изученных генов и обследованных больных мы представили общую концепцию прогнозирования коронарного риска с использованием дополнительных биомаркеров, включая генетические.
К ограничениям выполненного исследования относятся следующие:
— изучали ограниченный спектр генов на небольшой группе пациентов;
— в выборе полиморфизмов руководствовались данными литературы;
— у большинства пациентов из контрольной группы имелись ФР развития ИБС, что может не отражать ситуацию в популяции в целом.
Заключение
1. Результаты выполненного исследования позволяют сделать следующие предварительные выводы:
2. Анализ факторов риска развития ишемической болезни сердца с использованием методов распознавания по прецедентам является перспективным методом для стратификации риска заболевания и поддержки принятия оптимальных решений о профилактике.
3. Точность распознавания варьирует от 70—75% при малом числе признаков до 90% на информативных признаковых подсистемах.
4. Использование коллективов из различных методов прогнозирования позволяет повысить точность прогноза. Алгоритм голосования показывает максимальную точность прогноза относительно отдельных алгоритмов.
5. При оценке риска развития ишемической болезни сердца в большинство информативных систем признаков входят генетические маркеры, наиболее значимый из которых — генетический индекс, представляющий собой суммарное количество имеющихся полиморфных маркеров + семейный анамнез.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}